If you want to create a map of most used emojis in tweets about Australia bushfires, you should go with the following tasks:
Data collection from Twitter;
Defining of location for each user (we can use check-ins and location field from user-profile);
Emoji extraction (we are interested only in emojis those users used in tweets, only these will be counted);
Visualization (we want to allocate emojis on the map by each country). So, let’s start.
Twitter application
Twitter is very friendly to data collection. You can use its API. To do this, you need to make an application here. Also, you need to have a Twitter account.
If you have Twitter-app, open Details, tab “Keys and tokens,” where you can find needed credentials:
I used the rtweet package to search posts about Australia bushfires. R has many packages that provide a connection to Twitter API, in particular, I use early twitteR package, but rtweet from ropenscience society more user-friendly and powerful. The main strength of the rtweet package is its ability to handle rate limits.
twitter_credentials.R - file contains CUSTOMER_KEY, CUSTOMER_SECRET, ACCESS_TOKEN, and ACCESS_secret those you can receive from twitter application.
rtweet package provides functions that are easy to use and powerful for data extraction from Twitter. You need only to create a token for connection to Twitter API and use search_tweets function to search tweets for a defined period (Twitter API has a limitation on the last 6-9 days).
I created a vector with hashtags about Australian bushfires called terms and searched all tweets with them. I used the code below:
Code
suppressPackageStartupMessages({require(rtweet)require(ore)require(dplyr)require(ggplot2)require(ggtext)require(rvest)})source("scripts/twitter_credentials.R") # Contains API keys via Sys.getenv()token <-create_token(app ="twittScrap",consumer_key = CUSTOMER_KEY,consumer_secret = CUSTOMER_SECRET,access_token = ACCESS_TOKEN,access_secret = ACCESS_secret)terms <-c("prayforaustralia", "australiaonfire", "australiafires", "australia", "australianbushfire", "australianfires", "australiaburning", "australiaburns", "pray4australia", "australiabushfires", "prayforrain" )aus <-search_tweets(q =paste(terms, collapse =" OR "), n =10^10, include_rts =FALSE, retryonratelimit =TRUE, since ="2020-01-01", until ="2020-01-06")readr::write_rds(aus, "data/aus_bushfires.rds")
Let’s look at the collected data:
Code
aus <- readr::read_rds("australia_new2.rds") %>%select(user_id, status_id, location, created_at, coords_coords, text)skimr::skim(aus)
Data summary
Name
aus
Number of rows
143998
Number of columns
6
_______________________
Column type frequency:
POSIXct
1
character
4
list
1
________________________
Group variables
None
Variable type: POSIXct
skim_variable
n_missing
complete_rate
min
max
median
n_unique
created_at
0
1
2020-01-07 03:12:34
2020-01-07 23:59:59
2020-01-07 14:41:49
63090
Variable type: character
skim_variable
n_missing
complete_rate
min
max
empty
n_unique
whitespace
user_id
0
1
2
19
0
113529
0
status_id
0
1
19
19
0
143989
0
location
0
1
0
148
39654
36352
43
text
0
1
9
978
0
143316
0
Variable type: list
skim_variable
n_missing
complete_rate
n_unique
min_length
max_length
coords_coords
0
1
275
2
2
I have 1 293 284 tweets, but not all are interesting to us. Firstly, I only need tweets with known location (coordinates, city, country). Secondly, I only need tweets with emojis.
At first, I tackle the location problem.
Locations
I use OpenStreetMap API to convert location names to geographical coordinates. To do it, I run geocode_OSM from the tmaptools library. Note: OSM API has limit one request per second.
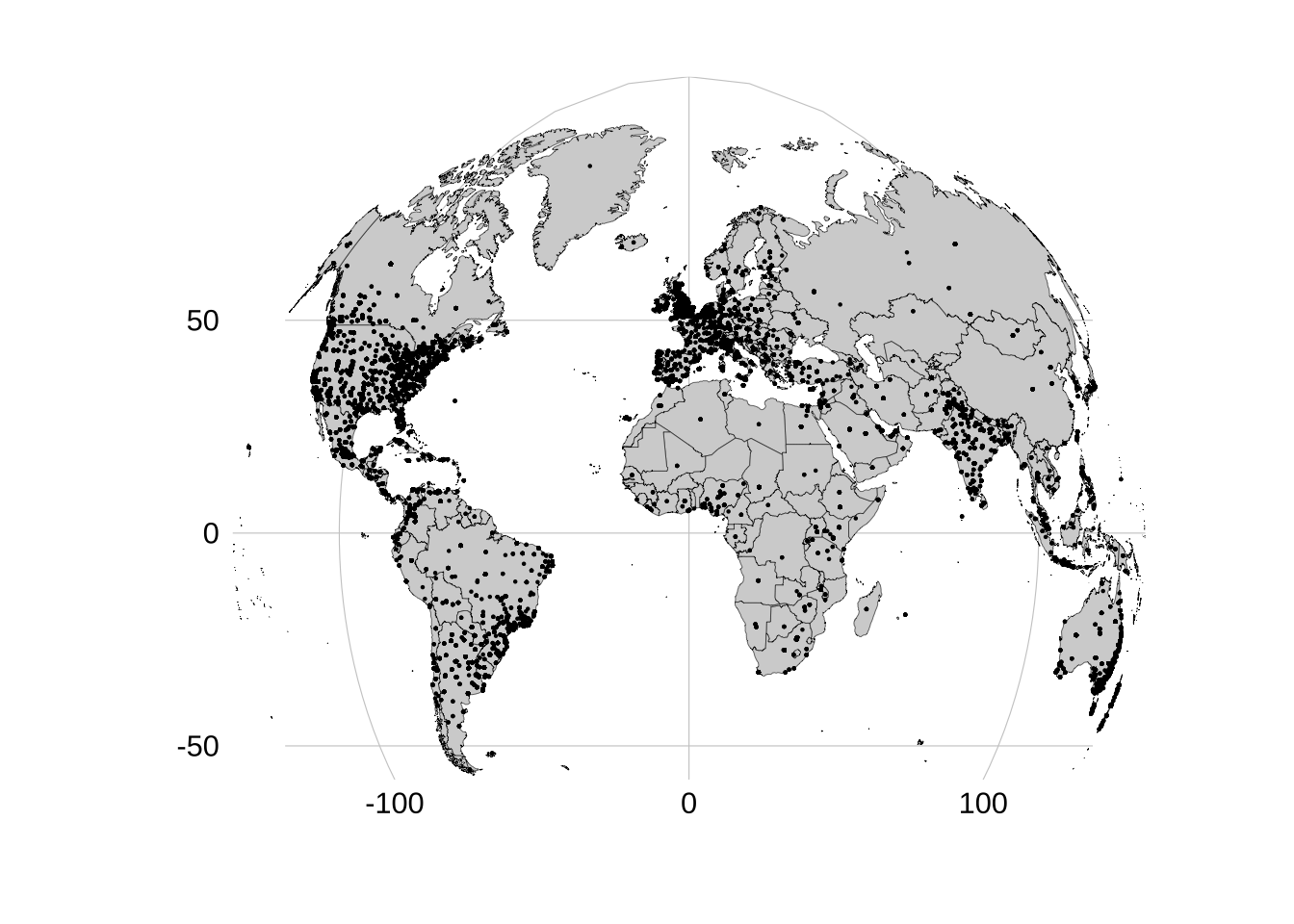
So I can apply these functions and get a data frame with coordinates for each tweet as a result. I will draw your attention to the fact that some tweets already have coordinates in coords_coords variable. For these tweets, I extract these values.
You can download images with these emojis from emojipedia (we need images to visualize them on the map). I did it using functions from the rvest package. The function emoji_to_link gets a URL for each emoji that you can use to download and visualize images of emojis. The function link_to_img provides a conversion path of each downloaded image to markdown format that I use in the plot.
Let’s create the map using functions from ggplot2 package:
Code
ggplot() +geom_polygon(data = world, aes(long, lat, group = group), color ="black", fill ="lightgray", linewidth =0.1) +geom_richtext(data = top_emo %>%ungroup(),# %>%#mutate(label = stringr::str_replace_all(label, "'25'", paste0("'", round(log1p(top_emo$n) * 3), "'"))),aes(x, y, label = emoji), fill =NA, label.color =NA, label.padding = grid::unit(rep(0, 4), "pt"), family="EmojiOne" ) +coord_map(projection ="gilbert", ylim =c(85, -50), xlim =c(180, -180)) +xlab("") +ylab("") +labs(title ="<img src='https://em-content.zobj.net/thumbs/320/twitter/348/flag-australia_1f1e6-1f1fa.png' width='35'/> Australia bushfires in emojis",subtitle ="<br/>Emoji is basically like another language: it has its own rules, it can cover anything that comes to one's mind, <br/>you can build whole sentences using only those tiny faces and other symbols. While people were praying <br/>for Australia on Twitter they used plenty of emojis as well, but only few of them were the most common ones.<br/>The map below shows the emojis used most frequently by country in tweets with hashtags <span style='color:blue'>#prayforaustralia</span>, <br/><span style='color:blue'>#australiaonfire</span>, <span style='color:blue'>#australiafires</span>, <span style='color:blue'>#australia</span>, <span style='color:blue'>#australianbushfire</span>, <span style='color:blue'>#australianfires</span>, <span style='color:blue'>#australiaburning</span>, <span style='color:blue'>#australiaburns</span>, <br/> <span style='color:blue'>#pray4australia</span>, <span style='color:blue'>#australiabushfires</span>, <span style='color:blue'>#prayforrain</span><br>",caption = glue::glue("Data: twitter.com, {format(n_distinct(aus_emo, 'status_id'), big.mark = ' ')} tweets with marked location") ) + hrbrthemes::theme_ipsum(base_family ="Lato") +theme(panel.grid =element_blank(),axis.text =element_blank(),plot.title =element_markdown(size =35, face ="bold", colour ="black", vjust =-1),plot.subtitle =element_markdown(size =18, vjust =-1, lineheight =1.1) )
I also used the ggtext package to make markdown formatting in text labels, ggalt package that provides Winkel tripel map projection and hrbrthemes that provides awesome themes for ggplots.
Conclusion
Hurray, we have the map of top emoji by each country on Twitter!
Here I want to make a summary describing packages that I used to do this analysis.
I used the following libraries:
rtweet - for access to Twitter API;
ore - to create regular expressions;
dplyr - to manipulate data;
ggplot2 - to make pretty map;
ggtext - to make markdown labels in ggplot2;
rvest - for web-scraping;
readr - to read data from files;
skimr - to make beatiful data-summary;
stringr - for text transformations;
tmaptools - to search coordinates by location name;
rworldmap - to load world map;
sp - for maps manipulations;
purrr - package provides functional programming in R;
---title: "Twitter-emojis analysis. Australian bushfires case"description: | In this post, I describe my approach to Twitter-data collection and analyzing that I used to make emoji-map.author: - name: Roman Kyrychenko url: https://www.linkedin.com/in/kirichenko17roman/date: 2020-01-15format: html: toc: true code-tools: truetwitter: creator: "@KyrychenkoRoman"categories: - ggplot2 - emoji - map - Twittercreative_commons: CC BYimage: "distill-preview.png"citation: true---```{r setup, include=FALSE}knitr::opts_chunk$set(echo = T, message = FALSE, warning = FALSE)suppressPackageStartupMessages({ require(rtweet) require(ore) require(dplyr) require(ggplot2) require(ggtext) require(rvest) require(emojifont)})```## Task definitionIf you want to create a map of most used emojis in tweets about Australia bushfires, you should go with the following tasks:- Data collection from Twitter;- Defining of location for each user (we can use check-ins and location field from user-profile);- Emoji extraction (we are interested only in emojis those users used in tweets, only these will be counted);- Visualization (we want to allocate emojis on the map by each country). So, let's start.## Twitter applicationTwitter is very friendly to data collection. You can use its API. To do this, you need to make an application [here](https://developer.twitter.com/en/apps). Also, you need to have a Twitter account.If you have Twitter-app, open Details, tab "Keys and tokens," where you can find needed credentials:I used the `rtweet` package to search posts about Australia bushfires. R has many packages that provide a connection to Twitter API, in particular, I use early `twitteR` package, but `rtweet` from ropenscience society more user-friendly and powerful. The main strength of the `rtweet` package is its ability to handle rate limits.**twitter_credentials.R** - file contains `CUSTOMER_KEY`, `CUSTOMER_SECRET`, `ACCESS_TOKEN`, and `ACCESS_secret` those you can receive from twitter application.`rtweet` package provides functions that are easy to use and powerful for data extraction from Twitter. You need only to create a token for connection to Twitter API and use `search_tweets` function to search tweets for a defined period (Twitter API has a limitation on the last 6-9 days).I created a vector with hashtags about Australian bushfires called terms and searched all tweets with them. I used the code below:```{r twitter_download, eval=F, echo=T}suppressPackageStartupMessages({ require(rtweet) require(ore) require(dplyr) require(ggplot2) require(ggtext) require(rvest)})source("scripts/twitter_credentials.R") # Contains API keys via Sys.getenv()token <- create_token( app = "twittScrap", consumer_key = CUSTOMER_KEY, consumer_secret = CUSTOMER_SECRET, access_token = ACCESS_TOKEN, access_secret = ACCESS_secret)terms <- c( "prayforaustralia", "australiaonfire", "australiafires", "australia", "australianbushfire", "australianfires", "australiaburning", "australiaburns", "pray4australia", "australiabushfires", "prayforrain" )aus <- search_tweets(q = paste(terms, collapse = " OR "), n = 10^10, include_rts = FALSE, retryonratelimit = TRUE, since = "2020-01-01", until = "2020-01-06")readr::write_rds(aus, "data/aus_bushfires.rds")```Let's look at the collected data:```{r aus_bushfires_data}aus <- readr::read_rds("australia_new2.rds") %>% select(user_id, status_id, location, created_at, coords_coords, text)skimr::skim(aus)```I have 1 293 284 tweets, but not all are interesting to us. Firstly, I only need tweets with known location (coordinates, city, country). Secondly, I only need tweets with emojis.At first, I tackle the location problem.## LocationsI use OpenStreetMap API to convert location names to geographical coordinates. To do it, I run `geocode_OSM` from the `tmaptools` library. Note: OSM API has limit one request per second.```{r locs, eval=F, echo=T, eval=F}locs <- aus %>% group_by(location = stringr::str_to_lower(location)) %>% count() %>% arrange(desc(n))top_locs <- tmaptools::geocode_OSM(locs$location, as.data.frame = T)readr::write_rds(top_locs, "data/top_locs.rds")```So, when you have longitudes and latitudes for most tweets, you need to convert these coordinates to country names.The functions below provide conversion coordinates to the country name in which those coordinates appear.```{r coords2country}coords2country <- function(points) { countriesSP <- rworldmap::getMap(resolution = "low") ina <- is.na(points[[1]]) pointsSP <- sp::SpatialPoints(points[!ina, ], proj4string = sp::CRS(sp::proj4string(countriesSP))) res <- rep(NA, nrow(points)) res[!ina] <- as.character(sp::over(pointsSP, countriesSP)$ADMIN) res}```So I can apply these functions and get a data frame with coordinates for each tweet as a result. I will draw your attention to the fact that some tweets already have coordinates in coords_coords variable. For these tweets, I extract these values.```{r aus_det}top_locs <- readr::read_rds("top_locs.rds")aus_det <- aus %>% mutate( location = stringr::str_remove_all(stringr::str_to_lower(location), "#"), country = coords2country( tibble( lon = purrr::map_dbl(coords_coords, ~ .[1]), lat = purrr::map_dbl(coords_coords, ~ .[2]) ) ) ) %>% left_join(top_locs, by = c("location" = "query")) %>% mutate( country = if_else(is.na(country), coords2country(select(., lon, lat)), country) ) %>% filter( !is.na(country) & between( created_at, lubridate::ymd_hms("2019-12-31 00:00:00"), lubridate::ymd_hms("2020-01-07 23:59:59") ) )skimr::skim(aus_det)```You can also map these tweets on the map as follows:```{r point_plot}world <- map_data("world")ggplot() + geom_polygon(data = world, aes(long, lat, group = group), color = "black", fill = "lightgray", linewidth = 0.1) + geom_point(data = aus_det, aes(lon, lat), size = 0.1) + coord_map(projection = "gilbert", ylim = c(85, -50), xlim = c(180, -180)) + xlab("") + ylab("") + hrbrthemes::theme_ipsum() + hrbrthemes::theme_ipsum(base_family = "Lato") + theme( panel.grid = element_blank(), axis.text = element_blank() )```So, yet you should extract emojis for these tweets.## Emojis extraction and analysisTo detect emojis in text, you need a dataset with emojis that contains Unicodes for each emoji.Using this dataset, I created a regular expression to extract emojis from tweets.The function `extract_emojis` returns a list with emojis used in each tweet.```{r emoji}emoji <- readr::read_csv( "https://raw.githubusercontent.com/laurenancona/twimoji/gh-pages/twitterEmojiProject/emoticon_conversion_noGraphic.csv", col_names = F) %>% slice(-1)emoji_regex <- sprintf("(%s)", paste0(emoji$X2, collapse = "|"))compiled <- ore(emoji_regex)extract_emojis <- function(text_vector) { res <- vector(mode = "list", length = length(text_vector)) where <- which(grepl(emoji_regex, text_vector, useBytes = TRUE)) cat("detected items with emojis\n") chat_emoji_lines <- text_vector[where] found_emoji <- ore.search(compiled, chat_emoji_lines, all = TRUE) res[where] <- ore::matches(found_emoji) cat("created list with emojis\n") res}```Let's apply this function to your tweets:```{r emoji_extraction, eval=F, echo=T}aus_emo <- aus_det %>% mutate( emoji = extract_emojis(text) ) %>% filter(!sapply(emoji, is.null)) %>% tidyr::unnest(emoji)``````{r load_emo, include=FALSE}aus_emo <- readr::read_rds("aus_emo.rds")```We detect ```r nrow(aus_emo)``` emojis!```{r show_emo}skimr::skim(aus_emo)```I want to map emojis in the center of each country. To do it, I need the coordinates of those. We can do it in the following way:```{r centroids_df}centroids_df <- rworldmap::getMap(resolution = "high") %>% sf::st_as_sf() %>% #rgeos::gCentroid(byid = TRUE) %>% sf::st_centroid() %>% #as.data.frame(row.names = F) %>% as_tibble(rownames = "country")skimr::skim(centroids_df)```So let's calculate top emoji by each country:```{r top_emo, fig.width = 16, fig.height = 11, dpi = 500}top_emo <- aus_emo %>% group_by(country, emoji) %>% dplyr::count() %>% group_by(country) %>% top_n(1, wt = n) %>% dplyr::arrange(desc(n)) %>% left_join(centroids_df, by = "country") %>% group_by(country) %>% slice(1) %>% ungroup()skimr::skim(top_emo)```You can download images with these emojis from emojipedia (we need images to visualize them on the map). I did it using functions from the `rvest` package. The function `emoji_to_link` gets a URL for each emoji that you can use to download and visualize images of emojis. The function `link_to_img` provides a conversion path of each downloaded image to markdown format that I use in the plot.```{r top_emo_summ}top_emo$x <- (top_emo$geometry %>% sf::st_coordinates())[,1]top_emo$y <- (top_emo$geometry %>% sf::st_coordinates())[,2]```Thus we have all we needed for visualization.## VisualizationLet's create the map using functions from `ggplot2` package:```{r map, fig.width = 16, fig.height = 11, dpi = 500}ggplot() + geom_polygon(data = world, aes(long, lat, group = group), color = "black", fill = "lightgray", linewidth = 0.1) + geom_richtext( data = top_emo %>% ungroup(),# %>% #mutate(label = stringr::str_replace_all(label, "'25'", paste0("'", round(log1p(top_emo$n) * 3), "'"))), aes(x, y, label = emoji), fill = NA, label.color = NA, label.padding = grid::unit(rep(0, 4), "pt"), family="EmojiOne" ) + coord_map(projection = "gilbert", ylim = c(85, -50), xlim = c(180, -180)) + xlab("") + ylab("") + labs( title = "<img src='https://em-content.zobj.net/thumbs/320/twitter/348/flag-australia_1f1e6-1f1fa.png' width='35'/> Australia bushfires in emojis", subtitle = "<br/>Emoji is basically like another language: it has its own rules, it can cover anything that comes to one's mind, <br/>you can build whole sentences using only those tiny faces and other symbols. While people were praying <br/>for Australia on Twitter they used plenty of emojis as well, but only few of them were the most common ones.<br/>The map below shows the emojis used most frequently by country in tweets with hashtags <span style='color:blue'>#prayforaustralia</span>, <br/><span style='color:blue'>#australiaonfire</span>, <span style='color:blue'>#australiafires</span>, <span style='color:blue'>#australia</span>, <span style='color:blue'>#australianbushfire</span>, <span style='color:blue'>#australianfires</span>, <span style='color:blue'>#australiaburning</span>, <span style='color:blue'>#australiaburns</span>, <br/> <span style='color:blue'>#pray4australia</span>, <span style='color:blue'>#australiabushfires</span>, <span style='color:blue'>#prayforrain</span><br>", caption = glue::glue("Data: twitter.com, {format(n_distinct(aus_emo, 'status_id'), big.mark = ' ')} tweets with marked location") ) + hrbrthemes::theme_ipsum(base_family = "Lato") + theme( panel.grid = element_blank(), axis.text = element_blank(), plot.title = element_markdown(size = 35, face = "bold", colour = "black", vjust = -1), plot.subtitle = element_markdown(size = 18, vjust = -1, lineheight = 1.1) )```I also used the `ggtext` package to make markdown formatting in text labels, `ggalt` package that provides Winkel tripel map projection and `hrbrthemes` that provides awesome themes for ggplots.## ConclusionHurray, we have the map of top emoji by each country on Twitter!Here I want to make a summary describing packages that I used to do this analysis.I used the following libraries:- `rtweet` - for access to Twitter API;- `ore` - to create regular expressions;- `dplyr` - to manipulate data;- `ggplot2` - to make pretty map;- `ggtext` - to make markdown labels in `ggplot2`;- `rvest` - for web-scraping;- `readr` - to read data from files;- `skimr` - to make beatiful data-summary;- `stringr` - for text transformations;- `tmaptools` - to search coordinates by location name;- `rworldmap` - to load world map;- `sp` - for maps manipulations;- `purrr` - package provides functional programming in R;- `lubridate` - for date conversions;- `ggalt` - to make Winkel tripel map projection;- `hrbrthemes` - to make pretty `ggplot2` themes;- `glue` - for better text formatting.All calcutaion made in R version 3.5.2.